How to Count Popularity of Baby Names in Python
Assignment viii: Data visualization¶
Every bit we've discussed in class, there are many different means y'all can visualize information! Y'all've learned several techniques for data visualization in this class thus far. This assignment will focus explicitly on information visualization, and include more of an emphasis on plot customization.
The dataset we'll exist using in this assignment is the popular "Baby names" dataset from the Social Security Administration, available at http://ssa.gov/oact/babynames/limits.html. We'll be using a pre-candy dataset bachelor in the R package babynames , which is a long-class table of baby names from 1880 to 2017. Download the dataset from TCU Online and upload to Colab or your Drive. Adjacent, import the necessary libraries for this assignment, then read in the dataset and have a quick await:
import pandas every bit pd import seaborn every bit sns import matplotlib.pyplot as plt sns . set_style ( "white" ) # Modify the path below to your data path df = pd . read_csv ( 'information/babynames.csv' ) # Converting the year to integer for ameliorate display df = df . assign ( yr = df . year . astype ( int )) df . caput ()
| twelvemonth | sex | name | n | prop | |
|---|---|---|---|---|---|
| 0 | 1880 | F | Mary | 7065 | 0.072384 |
| 1 | 1880 | F | Anna | 2604 | 0.026679 |
| 2 | 1880 | F | Emma | 2003 | 0.020521 |
| 3 | 1880 | F | Elizabeth | 1939 | 0.019866 |
| 4 | 1880 | F | Minnie | 1746 | 0.017888 |
The data frame has the following columns: year , which is the twelvemonth the baby was born; sex activity , the sexual practice of the baby; name , the proper name of the baby; n , the number of babies born with that name for that sex in that year; and prop , the proportion of babies of that sex in that year with that proper name. As you lot tin see, over 7 pct of female person babies in 1880 were given the proper name Mary! Now allow's take a wait at the size of our data frame.
Our data frame has 1.92 1000000 rows! Equally such, this isn't a dataset that you could reasonably deal with manually. Besides: Excel worksheets cannot handle data of this size, equally they take row limits of 1,048,576 rows, which takes us up to around 1989. This is not a dataset that is "big" past standard definitions, every bit information technology is only about 49 MB in size given the small number of columns. Nonetheless, information technology is much-better suited to a computational approach to information analysis like Python/ pandas .
Granted, with ane.ix million rows in our dataset, we'll demand to carefully consider our enquiry questions and how they tin help us cut downward the size of our dataset. In this notebook, I'd like you to get feel with three skills in Python plot customization:
-
Modifying nautical chart properties
-
Annotation/labeling
-
Small multiples
To practise this, we are going to focus on 3 topics:
-
What were the most popular names in 2017 (the concluding year in the dataset), and how did their popularity change over the past 10 years?
-
How does the release of Disney princess movies influence the popularity of baby names?
-
How have diverse gender-neutral names shifted in popularity between male & female person over time?
You'll then go a risk to do some of this on your own at the end of the assignment.
Question 1: What were the virtually popular names in 2017, and how did their popularity change over the past 10 years?¶
To get started with this question, we need to do some subsetting, which y'all are very familiar with by now. Let's wait specifically at males for this first question. First and foremost, however, nosotros need to effigy out the well-nigh popular male babe names in 2017. A few pandas /Python methods that you lot've learned in previous assignments can get this done.
Notice what we are doing hither - yous can think of the line of code as a concatenation of methods in which we are manipulating the df data frame in plow.
-
First, nosotros subset the data frame for only those male records in 2017;
-
Then, nosotros sort the data frame in descending social club by count;
-
Then, we slice the data frame to become back the meridian 15 rows;
-
Finally, we inquire
pandasto generate a list of names from our subsetted and sorted data frame.
# Subset for males in 2017 male17 = df . query ( 'year == 2017 & sexual activity == "M"' ) # Sort in descending social club of the number of names male17sorted = male17 . sort_values ( 'northward' , ascending = False ) # Piece the sorted data frame for the kickoff 15 rows top_male = male17sorted [ 0 : 15 ] # Pull the proper noun column from the sliced information frame and convert to a list name_list = top_male . name . tolist () name_list
['Liam', 'Noah', 'William', 'James', 'Logan', 'Benjamin', 'Bricklayer', 'Elijah', 'Oliver', 'Jacob', 'Lucas', 'Michael', 'Alexander', 'Ethan', 'Daniel']
pandas returns a Python list of the top 15 baby names in 2017 for boys. We can then pass this list to the .isin() method to get back entries for all of those names since 2000, and calculate their frequency per 1000 records in the dataset.
sub1 = ( df . query ( 'name in @name_list & year > 1999 & sex == "M"' ) . assign ( per1000 = df . prop * k ) ) sub1 . caput ()
| twelvemonth | sex | name | northward | prop | per1000 | |
|---|---|---|---|---|---|---|
| 1350393 | 2000 | M | Jacob | 34471 | 0.016514 | 16.51392 |
| 1350394 | 2000 | Chiliad | Michael | 32035 | 0.015347 | 15.34691 |
| 1350401 | 2000 | One thousand | Daniel | 22312 | 0.010689 | ten.68894 |
| 1350403 | 2000 | Thou | William | 20659 | 0.009897 | ix.89704 |
| 1350410 | 2000 | M | James | 17981 | 0.008614 | 8.61410 |
We are just virtually prepare to visualize the information now. At that place are multiple ways these data could be visualized; in this instance, we'll utilise a heatmap, which nosotros discussed in class. A heatmap is a grid of cells in which the shading of each prison cell is proportional to its value. By and large, darker cells represent a greater value. When applied to temporal data, it tin exist an effective style to prove the variation of values for multiple data series over fourth dimension.
Heatmaps in seaborn take a broad-format data frame with the y-values in the index, the ten-values every bit the columns, and the data values in the cells. We will use the .pivot() method to reshape our data and produce this type of data frame, then pass the dataframe to the heatmap() function.
wide1 = sub1 . pin ( alphabetize = 'proper noun' , columns = 'yr' , values = 'per1000' ) sns . heatmap ( wide1 )
<AxesSubplot:xlabel='twelvemonth', ylabel='proper name'> 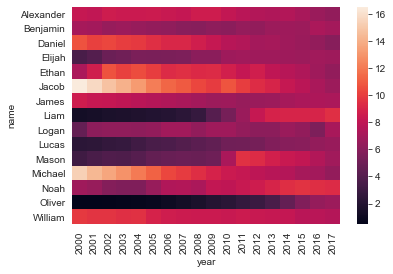
The plot looks prissy by default; we tin can run across some trends such as the ascension of Liam, Aiden, and Noah and the relative descent of Michael and Jacob (although both of those names are notwithstanding in the top 15, of course). However, you may notwithstanding want to customize your chart.
seaborn plots have many plot customization options born; y'all'll acquire how to utilise a few later on in the consignment. seaborn plots, however, are also matplotlib objects, which is the cadre plotting library in Python. In plow, you tin use the wealth of functions available in matplotlib to change your seaborn plots. You'll learn a few of those methods in this assignment.
Note the lawmaking below and what nosotros are doing. Nosotros'll import the pyplot module from matplotlib in the standard manner equally plt . pyplot gives us access to many dissimilar plot customization functions. We can set the figure size earlier calling the plotting function, and then rotate the x-tick labels, remove the axis labels, and add a championship to our chart. Also, notice the arguments passed to sns.heatmap() . The annot parameter allows us to annotate the heatmap with information values, and the cmap parameter allows usa to accommodate the colors. It accepts all ColorBrewer palettes as well as the built-in matplotlib palettes.
import matplotlib.pyplot as plt plt . effigy ( figsize = ( ten , 8 ), ) sns . heatmap ( wide1 , annot = True , cmap = 'Greens' ) plt . xticks ( rotation = 45 ) plt . ylabel ( "" ) plt . xlabel ( "" ) plt . championship ( "Most popular infant names - Male (rate per 1000)" )
Text(0.5, i.0, 'Most popular baby names - Male (rate per thou)') 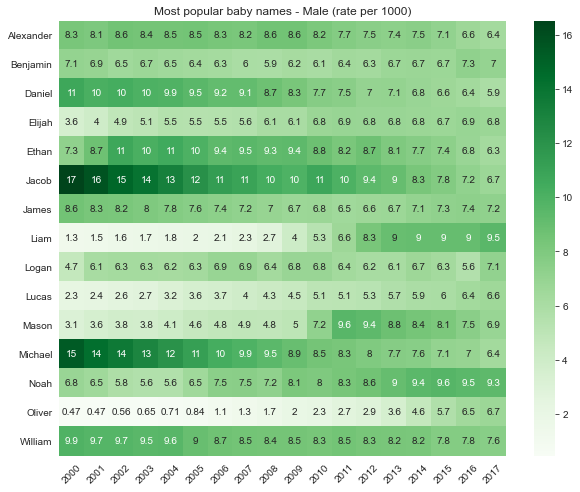
Question 2: How does the release of Disney movies influence the popularity of baby names?¶
Baby names tin sometimes be responsive to trends in popular civilisation. For example, "Daenerys" showed up in the dataset for the get-go time in 2012, and 82 infant girls were named Daenerys in 2015!. In this practice, we'll examine how the release of Disney Princess movies relates to baby names.
Allow'due south examine trends in female baby names since 1980 for four Disney Princess names: Jasmine, Ariel, Elsa, and Tiana.
sns . set_style ( "darkgrid" ) princesses = [ 'Jasmine' , 'Ariel' , 'Elsa' , 'Tiana' ] princess_df = ( df . query ( 'name in @princesses & sex == "F" & year > 1979' ) . assign ( per1000 = df . prop * 1000 ) ) princess_df . head ()
| year | sex | proper name | northward | prop | per1000 | |
|---|---|---|---|---|---|---|
| 864036 | 1980 | F | Jasmine | 1187 | 0.000667 | 0.66672 |
| 864335 | 1980 | F | Tiana | 377 | 0.000212 | 0.21175 |
| 864519 | 1980 | F | Elsa | 243 | 0.000136 | 0.13649 |
| 864674 | 1980 | F | Ariel | 181 | 0.000102 | 0.10166 |
| 883456 | 1981 | F | Jasmine | 1400 | 0.000783 | 0.78290 |
Clearly, Jasmine was a popular name in the early 1980s prior to the release of Aladdin. Tiana, Ariel, and Elsa, however, were not equally popular. So how did their popularity shift over time?
Nosotros'll make a line chart using the lineplot() function in seaborn . sns.lineplot() takes a long-form data frame similar our babynames data frame forth with a mapping of x and y values for a given dataset. The hue argument, if specified, volition split up up the data into groups within a given cavalcade and plot a dissever line, with different colors, for each group.
sns . lineplot ( information = princess_df , x = "twelvemonth" , y = "per1000" , hue = "proper noun" )
<AxesSubplot:xlabel='year', ylabel='per1000'> 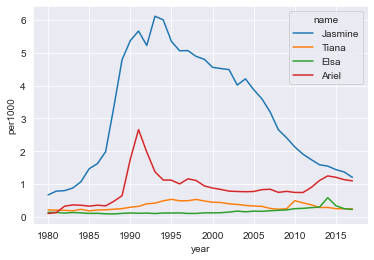
We can start to get a sense here of some "spikes" in the data - for example, a clear fasten in babies named Ariel is evident later 1989, which is when The Piddling Mermaid was released. We can also notation small spikes for Tiana and Elsa after the release of their corresponding movies.
Still - how tin we limited this on the chart in clearer terms? One way to accomplish this is through annotation, which refers to the placement of text on the plot to highlight particular data points. Before doing this, let's effigy out approximately what the values are for each princess proper noun when its moving-picture show was released:
disney_yrs = { 'Ariel' : 1989 , 'Elsa' : 2013 , 'Jasmine' : 1992 , 'Tiana' : 2009 } for princess , year in disney_yrs . items (): # Subset the data frame for princess and twelvemonth subset = princess_df . query ( 'name == @princess & year == @year' ) # Extract the value for per1000 with .values # .values returns a list, then we'll extract the 0th element value = subset . per1000 . values [ 0 ] impress ( princess + ': ' + str ( value ))
Ariel: 0.64461 Elsa: 0.2942 Jasmine: v.2262699999999995 Tiana: 0.24864
I accomplished this with a niggling new Python code. I've mentioned before the dict , a type of Python object enclosed in curly braces ( {} ) that can hold key-value pairs. The key comes before the colon, the value comes subsequently the colon, and each element of the dictionary is separated by a comma.
In this instance, our dictionary holds the name of the Disney princess, and the yr that the corresponding motion-picture show was released. Dictionaries can be iterated through with for and the .items() method; in this example, princess represents the key in the loop, and year represents the value. Within the loop, we can first create a princess and year-specific subset of our data frame, then excerpt the respective value from it.
Spend some time reading through the plt.annotate() code below so that you can empathise information technology. We're using a number of parameters here:
-
The annotation text is the first statement. Python will interpret the string '\n' as a line break, which allows us to put the text on multiple lines.
-
The
xyparameter refers to the data coordinates of the point we desire to annotate, given that nosotros've specified this with the'data'statement supplied to thexycoordsparameter. We'll apply the twelvemonth of the moving-picture show release for the X value, and the data values nosotros obtained above (approximately) for the Y value. -
In this example, withal, we don't want to put the text right on top of the lines themselves; as such, we can specify an commencement, and connect our text with the data point with an arrow. Nosotros use the
xytextandtextcoordsparameters to do this; have a look at the plot and see where this puts the text. The argument supplied toarrowprops, which are in the form of adict, govern the advent of the arrow.
Annotation often takes iteration and patience to become it correct. Try irresolute some of the arguments in the plt.annotate() calls below and see how the text and arrows move around!
# Set the figure size plt . figure ( figsize = ( 8 , 6 )) # Generate the chart sns . lineplot ( data = princess_df , x = "year" , y = "per1000" , hue = "name" ) # Build each note individually plt . annotate ( 'The Trivial \northward Mermaid' , xy = ( 1989 , 0.64 ), xycoords = 'data' , xytext = ( 1983 , 2.five ), textcoords = 'data' , arrowprops = dict ( arrowstyle = 'simple' ), fontsize = 10 ) plt . annotate ( 'Aladdin' , xy = ( 1992 , v.23 ), xycoords = 'information' , xytext = ( 1990 , 6.1 ), textcoords = 'data' , arrowprops = dict ( arrowstyle = 'simple' ), fontsize = ten ) plt . comment ( 'Frozen' , xy = ( 2013 , 0.294 ), xycoords = 'information' , xytext = ( 2011 , 2.five ), textcoords = 'information' , arrowprops = dict ( arrowstyle = 'unproblematic' ), fontsize = x ) plt . comment ( 'The Princess \n and the Frog' , xy = ( 2009 , 0.247 ), xycoords = 'data' , xytext = ( 2007 , ane.six ), textcoords = 'data' , arrowprops = dict ( arrowstyle = 'simple' ), fontsize = 10 ) plt . ylabel ( "Female baby names per m" , fontsize = 12 ) plt . xlabel ( "" ) plt . title ( "Influence of Disney movies on infant names" , fontsize = 15 ) plt . legend ( title = "" , fontsize = 12 )
<matplotlib.legend.Legend at 0x7f43a9133940> 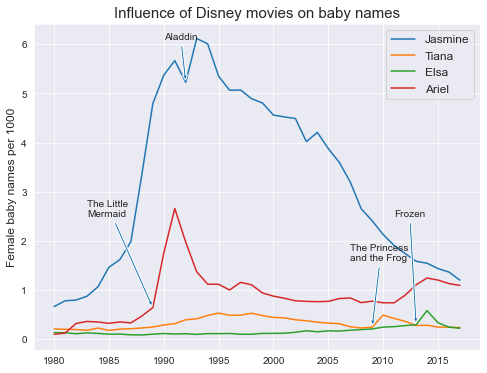
Question 3: How have gender-neutral names shifted in popularity between male and female person over time?¶
For the third and final question, we'll be looking at how four gender-neutral names have shifted between male and female over fourth dimension. Let's produce a new information frame from our original data frame that subsets for four popular gender-neutral names: Hashemite kingdom of jordan, Riley, Peyton, and Taylor. Nosotros'll take rows for years 1960 and later, and fill NaN values with 0.
neutral_names = [ 'Jordan' , 'Peyton' , 'Taylor' , 'Riley' ]
neutral_df = ( df . query ( 'proper name in @neutral_names & yr > 1959' ) . fillna ( 0 ) ) neutral_df . head ()
| yr | sex | name | n | prop | |
|---|---|---|---|---|---|
| 576603 | 1960 | F | Taylor | eleven | 0.000005 |
| 577863 | 1960 | F | Jordan | 7 | 0.000003 |
| 580462 | 1960 | Chiliad | Jordan | 137 | 0.000063 |
| 580537 | 1960 | M | Riley | 108 | 0.000050 |
| 580590 | 1960 | M | Taylor | 93 | 0.000043 |
In Assignment 6, you learned how to make faceted plots are available using the catplot() function, which is appropriate for charts that accept a categorical centrality. The companion relplot() function tin be used for plots with 2 continuous axes, such as scatterplots or lineplots. Let'south endeavor plotting faceted line charts that show how counts for these names vary by gender over time:
sns . relplot ( information = neutral_df , ten = "year" , y = "n" , hue = "sexual activity" , col = "name" , kind = "line" )
<seaborn.axisgrid.FacetGrid at 0x7f43b1f23d30> 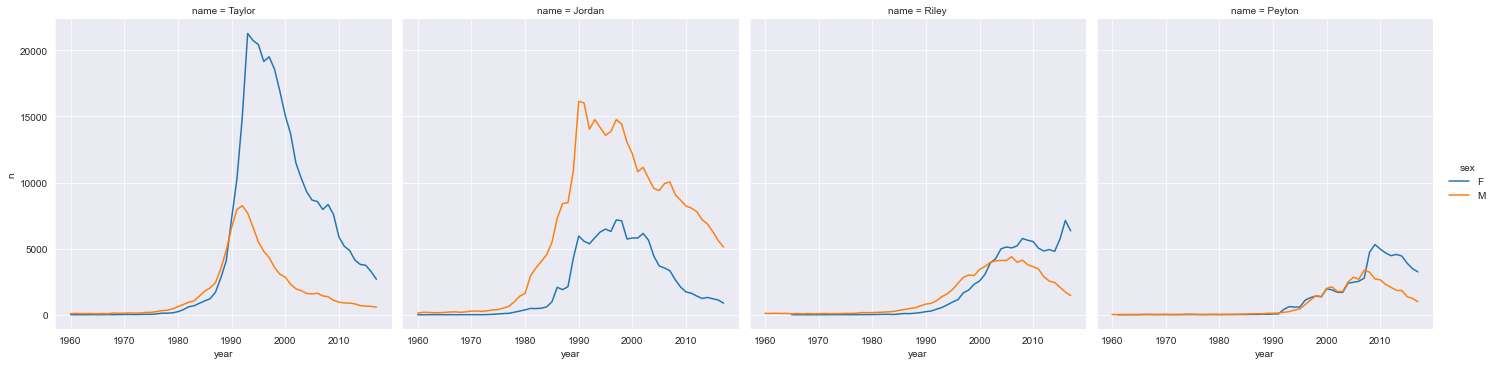
We tin can start to get a sense of some of the variations here; Taylor is more popular amidst girls than boys, whereas the opposite is true for Jordan. Let's brand a few modifications to the plot to improve its clarity. We volition add a col_wrap argument to specify how many columns to create in our plot grid. We can too change the colors with the statement supplied to palette , and nosotros can specify a height argument to modify the plot size.
Additionally, plot objects themselves accept methods that you can employ to alter the chart advent; we'll use .set_axis_labels() to better the look of our axes, and we can modify the title of the legend as well.
# Notation the font_scale statement that increases all font size by 25 percent sns . ready ( style = "white" , font_scale = 1.25 ) chart = sns . relplot ( data = neutral_df , x = "year" , y = "due north" , hue = "sex activity" , col = "proper name" , kind = "line" , col_wrap = two , palette = [ "darkred" , "navy" ], acme = iv ) chart . set_axis_labels ( 'Year' , 'Number of names' ) chart . _legend . set_title ( 'Sex' )
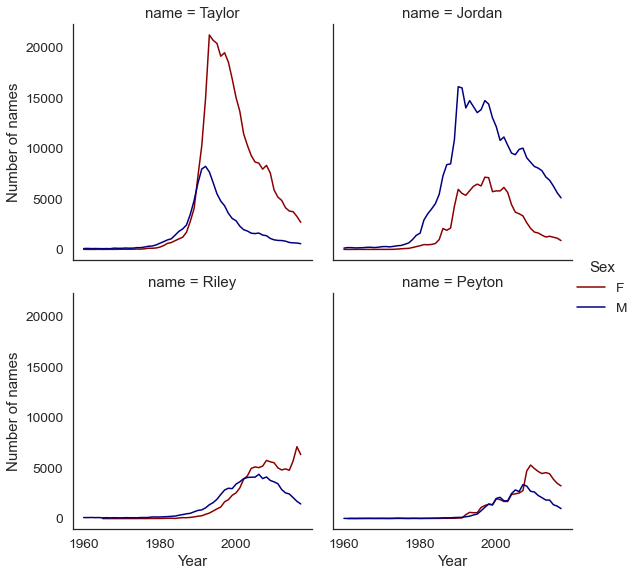
Exercises¶
To become credit for this assignment, you lot are going to apply what you've learned to some boosted tasks using the baby names dataset. Some of this will involve re-producing some of the analyses in the notebook, but for different prompts.
Exercise i: Re-create the heatmap from Question i, but this fourth dimension for females. What trends practice you detect?
Practice 2: Create a line chart that shows how a proper name of your choice has varied in popularity over fourth dimension. Discover out the year when your called proper name peaked in popularity, and annotate your chart to bear witness where this acme is located on the line.
Practise 3: In Question 2, we looked at the possible influence of Disney princess movies on female baby names. Option four other names (male or female) from popular culture over the past 30 years and produce a nautical chart that illustrates their influence (or lack thereof) on babe names. Exist strategic with your proper name decisions! You lot tin create a unmarried line chart with 4 series, or a small multiples chart with facets - selection the one you think is ideal!
Source: https://walker-data.com/geog30323/08-data-visualization.html
0 Response to "How to Count Popularity of Baby Names in Python"
Post a Comment